Wie oft und wie lange suchen Sie täglich nach Informationen? Ziemlich oft, wenn man vielen Studien glauben darf. Je nach Analyse verbringen Angestellte zwischen 1 und 2 Stunden am Tag mit der Suche nach Informationen. Und die Suche ist bei weitem nicht immer erfolgreich. Erst nach dem 3. oder 4. Versuch erhält die Hälfte der Suchenden im Schnitt eine Antwort auf ihre Fragen[1].
Der Aufwand für die Informationssuche in Unternehmen
Angesichts dieser Zahlen kann man nur darüber staunen, dass Unternehmen sich nicht intensiver mit der Verbesserung der Suche und Vermittlung von Informationen beschäftigen. Schließlich dreht sich in der heutigen digitalen Welt sehr viel um Wissen und Informationen. Nach Adam Riese geht es auch um viel Geld, denn diese 1-2 Stunden Informationssuche am Tag bedeuten 15-20% darauf verwendete Arbeitszeit, also relativ hohe Kosten, die sich durchaus reduzieren lassen. Umgekehrt kostet das Nicht-Finden von Informationen auch bares Geld. Jedes Unternehmen möchte, dass seine Kunden und Partner bequem und ohne Verzögerungen seine Produkte und Leistungen verstehen und finden.
Paradoxerweise wird es, je mehr Informationen wir produzieren, auch immer schwieriger sie zu finden. Es gibt sicherlich mehrere Schrauben, an denen man drehen kann, um Informationen besser zu gestalten, aber ein wichtiger Faktor, an dem niemand vorbeikommt, ist die Terminologie. Kernbaustein des Wissens sind die Termini, die zur Informationssuche, zum Wissensaustausch und zum Wissensaufbau verwendet werden. Viele Unternehmen sind sich dessen bewusst und bauen deswegen ihre Terminologie auf.
Intelligente Terminologien mit Begriffsrelationen
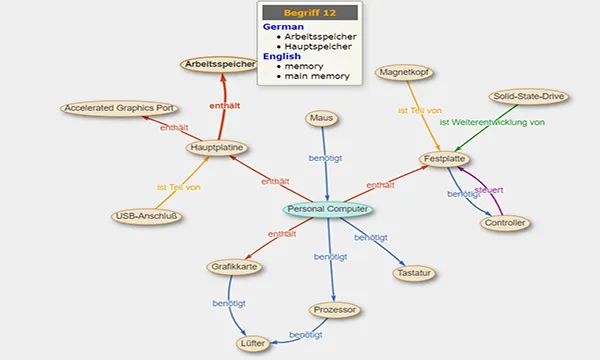
Noch wenig bekannt ist die Entwicklung intelligenter Terminologien, die allen Informationsspezialisten ganz neue Möglichkeiten eröffnen. Diese Art von Terminologien gibt es seit einigen Jahren unter verschiedenen Namen wie „intelligente Terminologien“, „wissensbasierte Terminologien“, „Ontoterminologien“, „Termontologien“, um nur einige zu nennen. Über Relationen verbinden sie die erfassten Begriffe in semantischen Netzwerken.
Heute sind begriffsbasierte Terminologiedatenbanken, wie sie Redaktionsabteilungen oder Language Services Provider (LSP) verwalten, weit verbreitet. Sie gehen von einem abstrakten Begriff aus und sammeln für jede Sprache jeweils alle Benennungen (Wörter, Abkürzungen oder Wortgruppen), die diesen Begriff bezeichnen.
Begriffsorientierte Terminologiebestände sind in vielen Fällen hilfreich. Z.B. bei der Suche nach Definition und Übersetzung eines Wortes wie Avalkredit oder Békésy-Audiometrie. Jedoch macht jeder ab und an die Erfahrung, dass in bestimmten Situationen die Angaben aus einem Terminologieeintrag für das Verständnis oder die Übersetzung eines Textes nicht ausreichen.
Kontext mit Relationen abbilden
Wie ist beispielsweise das Wort Behälter trotz korrekter Definition zu verstehen? Ohne den Behälter zu sehen oder eine detaillierte Beschreibung des Gegenstands zu haben, kann man nicht wissen was für ein Behälter gemeint ist. Es kann sich um eine Box für die Beförderung von Paketen oder um einen Flüssigkeitstank handeln. Entsprechend wird die Übersetzung sehr unterschiedlich ausfallen. Aber wenn der Begriff „Behälter“ mit anderen Begriffen in Verbindung steht, wird vieles klarer. Beispielsweise im folgenden Satz: „Sobald der Behälter leer ist, macht die Maschine keinen Kaffee mehr, bis frische Bohnen nachgefüllt sind.“
Die meisten heutigen Terminologiedatenbanken bieten keinen Mechanismus, um auf typische Nutzungssituationen zu reagieren. Auch tun sie sich schwer, dem Benutzer bei der Entscheidung zwischen alternativen Übersetzungen (übersetze ich Schwein nun mit pork oder mit pig?) zu helfen.
Faktoren wie der Kontext, der Zweck einer Information (welche Merkmale eines Begriffs sind relevant?) oder die verschiedenartigen sprachlichen Sichten der Realität beeinflussen Terminologie und Wissen.
Intelligente Terminologien haben sich von den Prozessen im menschlichen Gehirn inspirieren lassen, das Wissen in Neuronennetzen speichert. In Anlehnung an Ontologien verwenden intelligente Terminologien Relationen zwischen Begriffen und können diese nutzen, um typische Verwendungskontexte zu modellieren.
Relationen zwischen Begriffen revolutionieren die Informationssuche
Dank dieser Relationen bedeuten intelligente Terminologien einen Paradigmenwechsel für alle, die Informationen suchen oder vermitteln. Die hinterlegten Relationen verbunden mit allen Vorzügen der mehrsprachigen begriffsbasierten Terminologiearbeit erlauben ganz neue Methoden der Informationsverarbeitung.
Relationen helfen beispielsweise, Fragen wie die folgenden zu beantworten:
- Welche Teile muss ich abschrauben, um an den Sensor zu kommen?
- Was kann die Ursache für den Ausfall des Bauelementes sein?
Relationen wie „Ist_Teil_von“ oder „Beeinflusst“ liefern die Elemente für eine Antwort auf diese Fragen. Sie tragen zur Lösung von Aufgaben bei wie:
- Zusätzliches (d.h. implizites) Wissen über Relationen gewinnen
- Vorhandenes Wissen als semantisches Netzwerk speichern
- Überprüfung der korrekten Verwendung von Begriffen oder Übersetzungen im Kontext
- Unterstützung von Übersetzern oder Redakteuren bei der Recherche
Nutzungsszenarien für intelligente Terminologien
Es gibt unterschiedliche Wege, diese Aufgaben in der Praxis zu lösen. Eine erste Möglichkeit besteht darin, in XML-basierten Dokumenten Relationen zwischen Begriffen als Metadaten zu hinterlegen. Mit Hilfe dieser Metadaten können Anwendungen wie Chatbots oder Smart Assistenten verbundene Informationen erkennen und Handlungen ausführen, z.B. einem Nutzer, der nach einer Flugverbindung sucht, vernetzte Produkte wie Mietwagen oder Hotels anbieten.
Ferner können Annotationstools Informationen auf der Basis von Attributen und Relationen in Dokumenten hervorheben, die für den Benutzer wichtig sind. Beispiele: Alle Benennungen in einer Anleitung markieren, die eine Gefahrenquelle beschreiben oder alle Benennungen hervorheben, die Komponenten eines bestimmten Subsystems sind.
Ein weiterer Ansatz ist die Kontextprüfung unter Nutzung von Relationen. Viele Benennungen lassen sich je nach Kontext unterschiedlich auslegen. Dabei kann es sich um reine Homonyme handeln (Anlage, Rahmen) oder um Oberbegriffe wie Leistung. Hier können Tools wie ErrorSpy z.B. erkennen, dass die englische Übersetzung von Leistung mit power in einem bestimmten Kontext nicht passt, weil es sich um die Leistung eines Ladegeräts handelt. Hier passt kontextbedingt die Übersetzung capacity besser.
Aber eine Suche in der Terminologiedatenbank selbst hilft auch Redakteuren oder Übersetzern bei ihrer Arbeit. Die Visualisierung von Relationen zwischen Begriffen (oder Benennungen) liefert z.B. dem Übersetzer den passenden Hinweis für das Verständnis eines Begriffs oder für die richtige Übersetzung im Kontext (Spannvorrichtung wird mit tensioning device und nicht mit clamping device übersetzt, weil es eine Relation zu Riemen gibt).
Semantische Begriffsbeziehungen aufbauen
Es ist eine Herausforderung, semantische Beziehungen zwischen Begriffen aufzubauen, da dies Zeit und fundierte Fachkenntnisse erfordert. Durch die Mitarbeit aller am Aufbau einer Firmenterminologie beteiligten Spezialisten (Techniker, Redakteure, Übersetzer…), kann die Arbeit auf mehreren Schultern verteilt werden. Das Ergebnis steht sowohl Menschen als auch Maschinen zur Verfügung, was im Zeitalter von KI und Internet 4.0 immer wichtiger wird.
Intelligente Terminologien sind noch relativ neu. Bestehende Lösungen unterscheiden sich in der Vielfalt der Beziehungen, die sie modellieren, und in den Methoden, mit denen sie diese umsetzen. Es gibt noch kein Standardformat für den Datenaustausch intelligenter Terminologien. Der TBX-Standard (TermBase eXchange) kann keine Beziehungen darstellen und das RDF-basierte SKOS-Vokabular kann nur für manche Typen von Beziehungen verwendet werden.
Es bleibt einiges zu tun, aber das Spannende ist, dass intelligente Terminologien schon Realität sind und dass sie die Paradigmen der Terminologiearbeit verändern. Sie verbinden die Best Practices der Terminologiearbeit mit den Ansätzen von Ontologien und schließen die Lücke zwischen Terminologie und Wissen. Sie ebnen den Weg für völlig neue Dienstleistungsmöglichkeiten für Sprachspezialisten und helfen gleichzeitig Redakteuren und Übersetzern, ihre Arbeit effizienter zu gestalten.
[1] Hierzu gibt es sehr unterschiedliche Aussagen und Quellen. Z. B. Zahlen der www.aiig.org oder von http://www.bwd-it.com/various-survey-statistics-workers-spend-too-much-time-searching-for-information