
Künstliche Intelligenz revolutioniert die Übersetzungsbranche. Moderne Sprachmodelle übersetzen binnen Sekunden komplexe Texte, prüfen die Übersetzungsqualität und schlagen Verbesserungen vor. Ihre Ergebnisse wirken oft so natürlich und präzise, dass man leicht vergisst: Diese Systeme “verstehen” Sprache grundlegend anders als Menschen. Gerade bei anspruchsvollen Übersetzungsaufgaben führt dies zu überraschenden Fehlern und Inkonsistenzen.
Um zu verstehen warum, müssen wir einen Blick unter die Haube werfen: Wie funktionieren diese Systeme eigentlich, und wo liegen ihre strukturellen Grenzen?
Menschliche vs. maschinelle Sprachverarbeitung: Ein fundamentaler Unterschied
Menschen lernen Sprache nicht wie ein Lexikon. Wenn ein Kind das Wort “Apfel” lernt, verknüpft es dieses nicht nur mit einer Definition, sondern mit sinnlichen Erfahrungen: dem süßen Geschmack, dem knackigen Geräusch beim Beißen, der runden Form in der Hand. Diese verkörperte Spracherfahrung (embodied language) macht menschliches Sprachverständnis so reich und kontextabhängig.
Darüber hinaus prägen Bildung, Alter, persönliche Erfahrungen und kultureller Hintergrund unser Sprachverständnis fundamental. Menschen verstehen Humor, respektieren Tabus und erkennen historische oder sozialpolitische Referenzen. Sie können zwischen den Zeilen lesen und kulturelle Nuancen erfassen, die weit über die reine Wortbedeutung hinausgehen.
Sprachmodelle hingegen lernen aus Millionen von Textbeispielen statistische Muster. Sie erkennen, dass nach “Der Apfel ist” wahrscheinlich Wörter wie “rot”, “süß” oder “reif” folgen. Aber sie haben nie einen Apfel gesehen, geschmeckt oder gerochen. Ihr “Verständnis” basiert ausschließlich auf mathematischen Berechnungen über Worthäufigkeiten und Kontextmuster.
Ein praktisches Beispiel: Zwei gleichwertige Übersetzungen – zwei unterschiedliche Bewertungen
Betrachten wir zwei Sätze aus der Qualitätskontrolle einer technischen Übersetzung:
Original A: „Der Not-Aus-Schalter befindet sich rechts neben dem Bedienfeld.“
Übersetzung A: „The emergency stop button is located to the right of the control panel.“
Original B: „Der Not-Aus-Schalter ist unterhalb des Displays angebracht.“
Übersetzung B: „The emergency stop button is positioned below the display.“
Beide Übersetzungen sind fachlich korrekt und terminologisch sauber. Dennoch kann ein KI-System A als „technisch präzise“ und B als „nicht technisch genug“ bewerten.
Warum passiert das?
Wie Maschinen Bedeutung in Zahlen verwandeln
Um Text zu verarbeiten, müssen Sprachmodelle zunächst Wörter in eine für Computer verständliche Form bringen. Dieser Prozess erfolgt in mehreren Schritten:
Von Wörtern zu Tokens
Zuerst wird der Text in Tokens zerlegt – die kleinsten Verarbeitungseinheiten des Modells. Ein Token kann ein ganzes Wort (“Schalter”), ein Wortfragment (“Not-” und “Aus-”) oder sogar ein einzelnes Zeichen sein. Diese Tokenisierung erfolgt nicht nach linguistischen Regeln, sondern nach statistischen Häufigkeitsmustern im Trainingsdatensatz.
Embeddings: Die numerische Repräsentation
Diese Tokens werden dann in sogenannte Embeddings umgewandelt – hochdimensionale Zahlenvektoren (oft 12.000+ Dimensionen), die die Bedeutung im jeweiligen Kontext repräsentieren. Vereinfacht dargestellt könnte das so aussehen:
| Satz | Embedding für “Not-Aus-Schalter” |
| A | [0.51, 0.49, 0.32, …] |
| B | [0.50, 0.50, 0.31, …] |
Schon minimale Kontextunterschiede verändern diesen Vektor – ähnlich wie ein Fingerabdruck, der bei jeder Berührung leicht anders ist.
Das Kontextfenster: Begrenzte Aufmerksamkeitsspanne
Moderne Sprachmodelle können gleichzeitig nur eine begrenzte Anzahl von Tokens verarbeiten – ihr Kontextfenster. Während ein Modell vielleicht 50.000 verschiedene Tokens “kennt” (Vokabulargröße), kann es nur 8.000 bis 32.000 Tokens gleichzeitig “im Blick behalten”. Bei längeren Texten “vergisst” es frühere Inhalte.
Transformer und Attention: Wie Kontext entsteht
Der Transformer berechnet für jedes Token, auf welche anderen Tokens es achten soll (Self-Attention). Aus jedem Embedding entstehen drei Vektoren (Q, K, V), die bestimmen:
- Query (Q): “Wonach sucht dieses Token?”
- Key (K): “Wofür steht dieses Token?”
- Value (V): “Welche Information trägt dieses Token?”
Schon kleine sprachliche Änderungen wie „unten“ vs. „unterhalb“ erzeugen leicht unterschiedliche Aktivierungsmuster – und diese Änderungen pflanzen sich durch alle Schichten fort.
Die Mathematik hinter den Entscheidungen: Die Softmax-Funktion
Nachdem der Text viele nichtlineare Verarbeitungsschritte im neuronalen Netzwerk durchlaufen hat, erzeugt das Modell am Ende sogenannte Logits – unskalierte Zahlen, die lediglich relative Tendenzen ausdrücken, aber noch keine Entscheidung darstellen.
Die Softmax-Funktion wandelt diese Logits in echte entscheidbare Wahrscheinlichkeiten um, etwa „A hat eine Wahrscheinlichkeit von 50,01%, B hat eine Wahrscheinlichkeit von 49,99% ⇒ A gewinnt„).
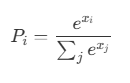
Was passiert hier mathematisch?
- xi: Logit-Wert einer bestimmten Option (z. B. „Terminologie korrekt“)
- e: die Eulersche Zahl (≈ 2,718), Basis der Exponentialfunktion
- Σj exj: Summe aller exponentiellen Logits – sorgt dafür, dass alle Wahrscheinlichkeiten zusammen 1 ergeben
- Pi: berechnete Wahrscheinlichkeit, dass diese Option die wahrscheinlichste ist
Dabei stellt die Softmax-Funktion zwei Dinge sicher:
- alle Werte werden positiv,
- und sie werden so normalisiert, dass ihre Summe genau 1 ergibt.
Erst dadurch entsteht eine entscheidbare Wahrscheinlichkeitsverteilung.
Warum dadurch Entscheidungen entstehen – und warum kleine Unterschiede große Wirkung haben können
Wenn zwei Optionen für uns Menschen praktisch gleichwertig sind – etwa zwei Übersetzungen oder zwei Fachtermini – unterscheiden sich ihre Logits oft nur minimal. Softmax verstärkt diese kleinen Unterschiede, indem sie aus (manchmal winzigen) Unterschieden in den Logits eine Entscheidung erzwingt.
Bei vielen möglichen Antworten verstärkt sich dieser Effekt
Wenn das Modell nicht nur zwischen zwei Antworten (z.B. richtig/falsch), sondern zwischen vielen Kandidaten entscheiden muss – etwa bei der Wortwahl aus einem großen Vokabular – führt dieselbe Mechanik dazu, dass ein eigentlich korrekter Terminus durch ein fast gleichwertiges Synonym ersetzt wird, weil dessen Logit minimal höher war.
Das erklärt einen großen Teil der beobachteten inkonsistenten Terminologie in KI-generierten Texten, nicht weil das Modell die Bedeutung nicht kennt – sondern weil die Softmax-Entscheidung selbst sensitiv auf kleinste Logit-Unterschiede reagiert.
Kurz zusammengefasst: Die scheinbare Inkonsistenz der Modelle entspringt direkt aus ihrer Architektur und ihrem Trainingsprozess und ist kein Fehlverhalten.
Warum das in der Praxis problematisch ist
Diese mathematisch bedingte Instabilität führt zu konkreten Problemen:
Das Problem der Terminologie-Inkonsistenz
Stellen Sie sich vor, ein medizinischer Text verwendet zunächst “Studienteilnehmer” und übersetzt dies korrekt mit “study participants”. Wenige Absätze später erscheint derselbe Begriff in einem minimal anderen Kontext: “Die Studienteilnehmer wurden randomisiert.” Plötzlich schlägt die KI “subjects were randomized” vor und markiert die ursprünglich korrekte Übersetzung sogar als Fehler.
Warum passiert das? In einem statischen Embedding-Modell mögen diese beiden Termini nahe beinander liegen. Im kontextuellen Flow eines transformerbasierten LLMs können ihre exakten Positionen im Vektorraum jedoch leicht verschoben sein, was dazu führt, dass einmal “study participants” und ein andermal “subjects” die marginal höhere Wahrscheinlichkeit erhält.
Konsistenz vs. Kontext: Ein unlösbarer Konflikt
Für Fachübersetzer ist terminologische Konsistenz essentiell. Ein einmal festgelegter Begriff sollte durchgängig verwendet werden. KI-Systeme hingegen optimieren jeden Satz isoliert für den jeweiligen Kontext. Sie erkennen nicht, dass “study participants” und “subjects” zwar beide korrekt, aber inkonsistent sind.
Das Spektrum der KI-Probleme geht weit über Terminologie hinaus
Neben Konsistenzproblemen zeigen sich weitere systemische Schwächen:
- Halluzinationen: KI-Systeme erfinden plausible, aber falsche Informationen, besonders bei Fachbegriffen oder seltenen Konzepten
- Eigennamenfehler: Namen von Personen, Orten oder Marken werden oft falsch übersetzt oder unlogisch angepasst
- Grammatikalische Inkonsistenzen: Aufgrund der Token-basierten Verarbeitung entstehen Flexionsfehler oder fehlende Kongruenz zwischen Satzteilen
- Kontextverlust: Pronomen und Verweise können falsch zugeordnet werden, wenn der relevante Kontext außerhalb des Verarbeitungsfensters liegt
Ein fundamentales Problem: Anweisungen sind keine Gesetze
Ein weiteres strukturelles Problem liegt in der Art, wie KI-Systeme mit Anweisungen umgehen. Anders als bei strukturierten Programmiersprachen mit fester Syntax, die vorhersagbare Ergebnisse liefern, folgen KI-Modelle Prompts nicht deterministisch.
Selbst explizite Anweisungen wie “Übersetze nur die Wörter, ändere keine Zahlen” werden nur probabilistisch interpretiert. Das System berechnet lediglich, wie wahrscheinlich es ist, dass eine bestimmte Antwort den Erwartungen entspricht – es führt keine Befehle im eigentlichen Sinne aus. Dies erklärt, warum selbst bei identischen Eingaben unterschiedliche Ergebnisse entstehen können.
Grenzen sind systembedingt, nicht technisch
Diese Probleme von KI-Modellen sind keine Kinderkrankheiten, die sich mit mehr Rechenleistung oder besseren Trainingsdaten lösen lassen. Sie sind strukturelle Eigenschaften der Funktionsweise von Sprachmodellen:
- Kein echtes Regelverständnis: Sprachmodelle befolgen keine festen Regeln, sondern berechnen Wahrscheinlichkeiten
- Kontextfenster-Beschränkungen: KI-Anwendungen neigen dazu, zu lange Kontexte zu vergessen – frühere Textteile verschwinden aus dem “Gedächtnis”
- Tokenisierung-Probleme: Zusammengesetzte Begriffe werden oft unintuitiv zerlegt. Beispiel: “Maschinenbauingenieur” könnte in “Maschinen”, “bau” und “ingenieur” aufgeteilt werden, wodurch der Gesamtbegriff seine einheitliche Bedeutung verliert. Dies führt zu fehlerhaften Übersetzungen zusammengesetzter Fachbegriffe.
- Fehlende Welterfahrung: Ohne sinnliche Erfahrung bleibt Bedeutung eine abstrakte Zahl ohne Bezug zur Wirklichkeit
Wie man trotzdem bessere Ergebnisse erzielt
Obwohl die Grundprobleme nicht lösbar sind, gibt es Strategien zur Verbesserung:
Chain-of-Thought-Prompting
Statt einer Gesamtaufgabe werden logische Einzelschritte definiert:
Umsetzungsbeispiel: ZAHLENANALYSE bei der Qualitätssicherung:
- “Extrahiere alle Zahlen aus dem Ausgangssegment (auch ausgeschriebene)”
- “Extrahiere alle Zahlen aus dem Zielsegment (auch ausgeschriebene)”
- “Vergleiche die Zahlenwerte – müssen identisch sein”
Few-Shot-Learning mit Beispielen
Das Modell erhält positive und negative Beispiele, die die gewünschten Muster verdeutlichen und die Wahrscheinlichkeitsverteilung stabilisieren.
Agentic AI: Spezialisierte Teilaufgaben
Verschiedene Modell-Instanzen übernehmen koordinierte Rollen – eine prüft Terminologie, eine andere Grammatik, eine dritte den Stil.
Integration externer Systeme
APIs und Datenbanken für normierte Terminologie werden direkt in den Übersetzungsprozess eingebunden. Dazu gehören auch Named-Entity-Datenbanken für Eigennamen oder spezialisierte Natural Language Processing-Bibliotheken wie spaCy, die grammatikalische Strukturen erkennen und linguistische Regeln durchsetzen können.
Warum Menschen unverzichtbar bleiben
Alle Optimierungen verbessern die Stabilität, lösen aber das Grundproblem nicht: KI simuliert Sprache, versteht sie aber nicht. In Situationen, die kulturelle Kompetenz, kreative Lösungen oder individuelle Urteilskraft erfordern, sind Menschen unverzichtbar.
Ein Beispiel: Soll “Mitnahmeverbot” mit “ban on transport”, “prohibition of carriage” oder “no taking along” übersetzt werden? Die Antwort hängt von Zielgruppe, Kontext und Dokumenttyp ab – Faktoren, die sich nicht aus Token-Wahrscheinlichkeiten ableiten lassen.
Die Stärken richtig nutzen
Sprachmodelle haben durchaus ihre Berechtigung – wenn man ihre Grenzen kennt:
- Terminologie-Extraktion aus großen Textmengen
- Erste Übersetzungsentwürfe mit anschließender Bearbeitung durch Humanübersetzer
- Semantische Prüfung von Übersetzungen
- Stilistische Vereinheitlichung von Texten
Der Schlüssel liegt im bewussten Einsatz: KI als mächtiges Werkzeug in den Händen kompetenter Fachkräfte, nicht als Ersatz für menschliche Expertise.
Fazit: Verstehen statt verdammen
Large Language Models sind beeindruckende Technologien mit klaren strukturellen Grenzen. Diese Grenzen sind nicht Schwächen der aktuellen Generation, sondern mathematisch bedingte Eigenschaften ihres Funktionsprinzips.
Wer diese Grenzen versteht, kann KI-Systeme gezielt und erfolgreich einsetzen: als schnelle, skalierbare Assistenten in einem fachlich verantworteten Übersetzungsprozess. Die Zukunft liegt nicht im Kampf Mensch vs. Maschine, sondern in der intelligenten Kombination beider Stärken.