
AntConc ist ein leistungsfähiges Werkzeug zur Textanalyse und Terminologieextraktion, das Übersetzern und technischen Redakteuren große Dienste erweisen kann. Im ersten Teil unseres Artikels über Terminologieextraktion mit AntConc haben wir beschrieben, wie das Programm funktioniert und wie Übersetzer oder Redakteure Informationen und Terminologie aus Texten gewinnen können. Wir haben die Hauptfunktionen des Programms beschrieben und erklärt, wie man Wort- und Mehrwortlisten, Kollokationen und Wortkontexte (KWIC) extrahiert.
In diesem zweiten Teil konzentrieren wir uns auf erweiterte Funktionen wie die linguistische Wortsuche und die Erkennung von Schlüsselwörtern. Diese Funktionen unterstützen eine tiefer gehende Analyse von Terminologiemustern und die Erkennung von fachspezifischen Begriffen. Wir erläutern auch einige fortgeschrittene Aspekte von AntConc, die eine gezieltere Terminologieextraktion ermöglichen (z. B. auf der Grundlage regulärer Ausdrücke).
Linguistische Terminologieextraktion mit AntConc
Linguistische Methoden der Terminologieextraktion verwenden verschiedene linguistische Techniken, wie Part-of-Speech-Tagging, syntaktische und semantische Analyse, um relevante Begriffe auszuwählen. Diese Techniken ermöglichen es, Muster und Strukturen in Texten zu erkennen, die für die Fachterminologie typisch sind.
Part-of-Speech-Tags kennzeichnen jedes Wort in einem Korpus mit seiner syntaktischen Rolle (z. B. Adjektiv, Artikel, Präposition usw.). Dieses Part-of-Speech-Tagging (POST) wird in der Regel automatisch mit Hilfe künstlicher Intelligenz durchgeführt. Dies geschieht mit einem intelligenten Sprachmodell, das mit manuell annotierten Daten in einer Sprache trainiert wurde und so die syntaktische Funktion einzelner Wörter gelernt hat.
Die syntaktische Terminologieextraktion nutzt diese Informationen, um nach bestimmten Mustern zu suchen, die für Termini in bestimmten Fachgebieten oder Sprachen charakteristisch sind. Das Tool AntConc kann diesen Ansatz durch seine linguistische Suchfunktion unterstützen, die es ermöglicht, Muster wie “Adjektiv + Substantiv” oder “Adjektiv + Substantiv + Substantiv” in linguistisch annotierten Texten zu finden.
Es gibt mehrere verschiedene POS-Tagger, die alle ihre Vor- und Nachteile haben. Wer zum Beispiel programmiert und die Programmiersprache Python verwendet, findet unter anderem in der Spacy-Bibliothek eine große Auswahl an POS-Taggern. Für Nutzer ohne Programmierkenntnisse bietet TagAnt, ein kostenloses Programm des AntConc-Entwicklers Laurence Anthony, sehr gute Dienste. Es verfügt über eine Benutzeroberfläche und fügt Wörtern in Texten Part-of-Speech (POS)-Tags hinzu. Durch das Annotieren mit solchen Tags können komplexe Suchanfragen in AntConc ausgeführt werden.
Praktische Umsetzung der linguistischen Terminologieextraktion mit AntConc
Erster Schritt: Part-of-Speech (POS)-Tagging mit TagAnt
AntConc benötigt für die linguistische Suche einen mit POS-Tags annotierten Korpus. TagAnt ist ein Werkzeug, das diese wichtige Vorarbeit leistet. Es ist kostenlos erhältlich unter https://www.laurenceanthony.net/software/tagant/.
Um eine getaggte Datei mit TagAnt zu erstellen, gehen Sie wie folgt vor:
- Importieren Sie Ihren Text in TagAnt.
- Wählen Sie die Sprache Ihres Textes.
- Entscheiden Sie, welche Informationen generiert werden sollen. Wir empfehlen: ” word+pos_tag+lemma” (Wort, Tag für die syntaktische Funktion, Grundform des Wortes).
- Definieren Sie das Ausgabeformat: Für die Weiterverarbeitung in AntConc wählen Sie das horizontale Format, in dem die Wortbestandteile mit Unterstrichen verbunden sind (z. B. „Terminologie_NN„).
- Klicken Sie auf “Start” und exportieren Sie dann das Ergebnis.
Hinweis: TagAnt erstellt automatisch ein Unterverzeichnis “tagged”, in dem es die annotierte Datei speichert.
Sie können nun das mit POS-Tags annotierte Korpus in AntConc laden und weiterverarbeiten.
Zweiter Schritt: Konfiguration des Terminologieextraktionsprojekts
Nach der Annotation mit TagAnt können Sie nun das annotierte Korpus in AntConc laden. Dazu müssen Sie ein neues Korpus einrichten und es so konfigurieren, dass es die POS-Tags erkennen kann. Verwenden Sie dazu den “Corpus Manager”, den Sie im Dateimenü finden. Die folgenden Einstellungen sollten Sie besonders beachten:
- Indexer: Für annotierte Dateien wählen Sie den “simple_word_pos_headword_indexer”, der POS-Tags und Lemmata (Basisform eines Wortes) verarbeiten kann.
- Encoding: UTF-8 ist Standard.
- Token Definition: Entscheiden Sie, wie Sie ein Token (Wort) in Ihrem Korpus definieren. Sie können Standardzeichenklassen, benutzerdefinierte Zeichen oder Regex verwenden, um zu definieren, was das Programm als ein Wort betrachten soll (z.B. Zahlen oder Wörter mit Sonderzeichen ausschließen).
Wenn Sie alle Einstellungen vorgenommen haben, können Sie auf “Create” und dann auf “Return to Main Window” klicken und Ihr Korpus ist erstellt.
Dritter Schritt: Definition von linguistischen Mustern zur Filterung von Termkandidaten
Die Muster hängen von der jeweiligen Sprache und dem Fachgebiet ab. Um diese Muster zu bestimmen, können Sie z. B. die vorhandene Terminologie in Ihrem Fachgebiet analysieren und sehen, welche syntaktische Muster auftreten.
POS-Tagger verwenden spezifische Tags, oft mit mehreren Varianten für allgemeinere Wortklassen wie VERB. Diese Tags müssen entsprechenden Mustern zugeordnet werden. Beispielsweise generiert die Nutzung von TagAnt Tags, die mit denen von SpaCy vergleichbar sind. So werden für Substantive Tags wie “NNP” (Eigenname) und “NN” (normales Substantiv) verwendet.
Im Englischen setzt SpaCy das Universal Dependencies (UD) Tagset mit 17 Haupt-POS-Tags ein, die grundlegende Wortarten wie Nomen, Verben, Adjektive und Adverbien abdecken. Zusätzlich zu diesen Haupt-POS-Tags bietet SpaCy detailliertere Tags und Attribute für grammatikalische Feinheiten. Dazu gehören Tags für Zeitformen bei Verben, Kasus bei Nomen und Komparativ- sowie Superlativformen bei Adjektiven. Ein Beispiel für das Ergebnis der fünf häufigsten Muster in der Terminologie des Maschinenbaus ist:
- Nomen: wattmeter
- Nomen + Nomen: steel bottle
- Nomen + Nomen + Nomen: filter pressure control
- Adjektiv + Nomen: positive connection
- Partizip + Nomen: working hour
Vierter Schritt: Terminologieextraktion nach linguistischen Mustern
So gehen Sie vor, wenn Sie zum Beispiel nach der Kombination “NN” + “NN” (Nomen + Nomen) suchen:
Die Datei, die Sie mit AntConc analysieren, ist kein reiner Text, sondern eine Kombination aus Wörtern und POS-Tags. Sie können in den globalen Einstellungen festlegen, wie die Ergebnisse angezeigt werden sollen, z.B. nur die gefundenen Termini oder zusätzliche linguistische Informationen. Sie können dies über den Menüpunkt “Tag” in den globalen Einstellungen konfigurieren, indem Sie AntConc anweisen, in den Ergebnissen das Basiswort (Lemma, in AntConc “headword” genannt) oder das extrahierte Wort (“type”) entweder allein oder in Kombination mit dem POS-Tag anzuzeigen. Wenn Sie gleich die Grundform haben möchten, verwenden Sie die Option “headword” und klicken Sie auf die Schaltfläche “set for all tools”.
Bevor Sie die eigentliche linguistische Suche im Reiter “N-Gramm” oder “Word” starten, definieren Sie die Suchparameter. Die Suchfunktionen von AntConc ermöglichen Ihnen die Suche nach Wörtern, Groß- und Kleinbuchstaben und regulären Ausdrücken.
Sie können nun Ihre Suchanfrage in das Suchfeld eingeben, zum Beispiel “*_NN*_NN” für Nomen + Nomen. Ein Sternchen vor dem Unterstrich bedeutet, dass alle Zeichen vor dem Tag “NN” ausgewählt werden, etwa so: *_NN
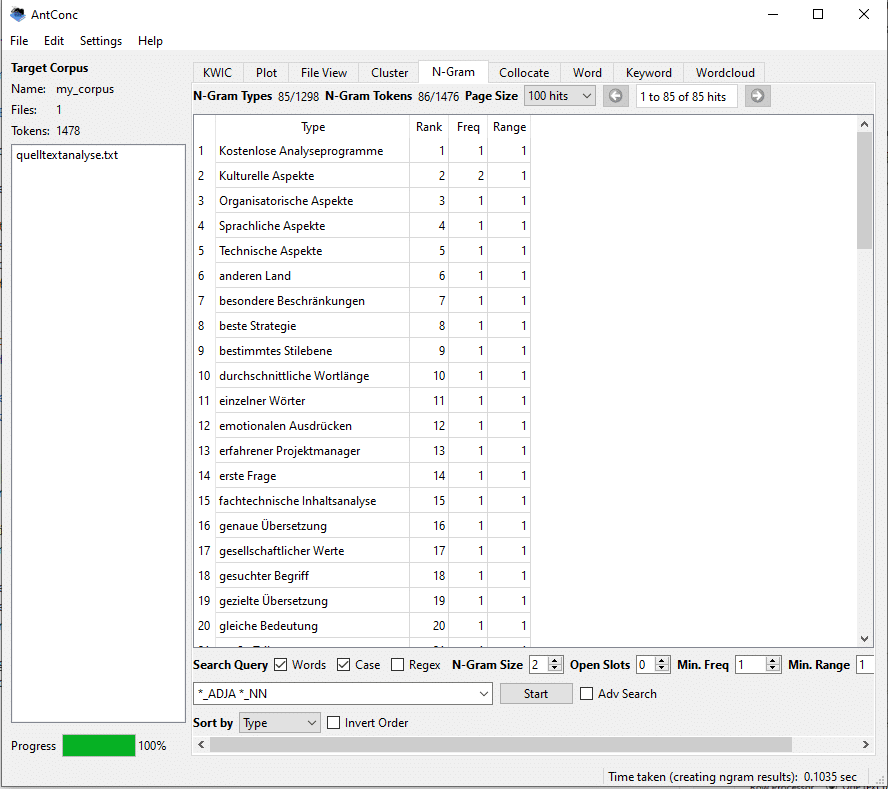
Die nächsten Schritte sind dieselben, die wir sie im ersten Teil für die normale Terminologieextraktion erklärt haben. Schließlich können Sie die extrahierte Terminologie exportieren und für den Import in Terminologieverwaltungssysteme vorbereiten. Wenn Sie verschiedene Tag-Kombinationen gleichzeitig abfragen und exportieren möchten, können Sie die erweiterte Suche (Adv Search) aktivieren (Kontrollkästchen neben dem Suchfeld).
Suche nach fachspezifischen Termkandidaten in AntConc
Eine Keyword-Suche wird in der Regel durchgeführt, um fachliche Termini aus einem bestimmten Bereich zu extrahieren. Der Grundgedanke ist der, dass der Fachtext mit einem allgemeinsprachlichen Korpus verglichen wird und die Wörter, die “herausstechen”, extrahiert werden. Dazu vergleichen Tools wie AntConc die Häufigkeit der Wörter im Korpus mit einem Referenzkorpus. Im Zusammenhang mit diesem Verfahren wird der Begriff “Keyness” oder “Keywordness” verwendet. Eine gängige Methode zur Berechnung von Keyness ist die Verwendung der Formel für die Log-Likelihood (G^2), die wie folgt lautet:
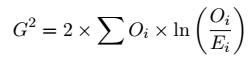
Hier bedeutet:
- ( G^2 ): Das Ergebnis, d.h. der Wert der Loglikelihood.
- ( O_i ): Die beobachtete Häufigkeit eines Wortes im untersuchten Text.
- ( E_i ): Die erwartete (“normale”) Häufigkeit des Wortes, basierend auf dem Referenzkorpus.
- ( ln): Der natürliche Logarithmus.
Ein hoher Wert von ( G^2 ) zeigt an, dass das Wort im Zielkorpus im Vergleich zum Referenzkorpus signifikant häufiger (oder seltener) vorkommt, was darauf hindeuten kann, dass es sich um ein relevantes Fachwort in diesem Kontext handelt.
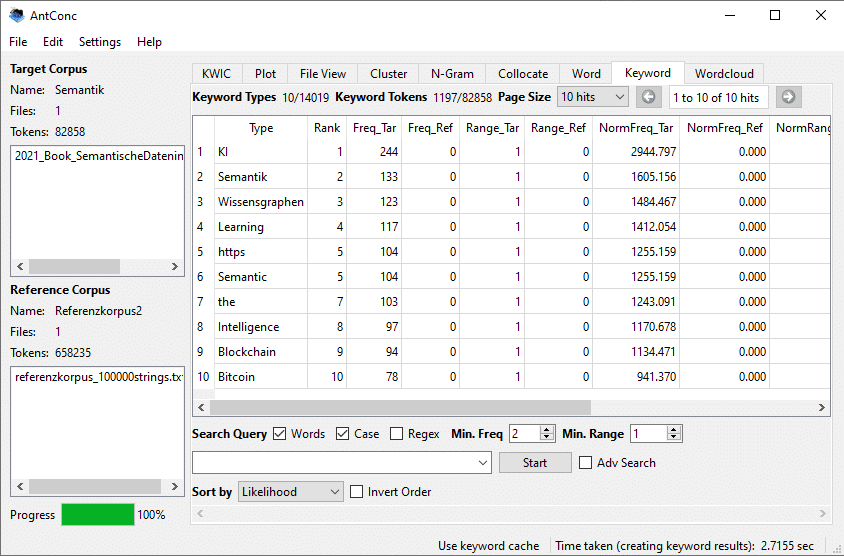
Implementierung der statistischen Keyword-Ermittlung mit AntConc
Schritt 1: Definition eines Referenzkorpus
Für die Keyword-Ermittlung wird zunächst ein geeignetes Referenzkorpus benötigt. Dies ist in der Regel ein allgemeinsprachliches Korpus. Es können aber auch andere Themen sein, zum Beispiel wenn Sie die Fachsprache zweier Fachgebiete vergleichen wollen. Es gibt mehrere öffentlich zugängliche Quellen für Korpora, die man kostenlos herunterladen kann. Zwei Adressen sind z.B. die Korpora der Universität Leipzig http://wortschatz.uni-leipzig.de/ und das DWDS-Kernkorpus https://www.dwds.de/.
Sobald Sie die Daten gesammelt haben, die Sie als Referenzkorpus verwenden möchten, erstellen Sie ein Korpus auf die gleiche Weise wie ein Korpus für die Terminologieextraktion. Um diese Daten dann für die Keyword-Analyse zu verwenden, gehen Sie zum “Corpus Manager”, öffnen Sie zunächst das Korpus, aus dem Sie Schlüsselwörter extrahieren möchten, und klicken Sie im rechten Bereich auf die Registerkarte “Reference corpus”. Wenn diese Registerkarte aktiv ist, klicken Sie im linken Bereich auf das Referenzkorpus. Der Korpusname und die Konfigurationsinformationen werden angezeigt. Sie können dann auf die Schaltfläche “return to main window ” klicken und die Extraktion starten.
Schritt 2: Konfiguration der Keyword-Suche in AntConc
Anschließend können Sie die mathematischen Parameter für die Keyword-Suche in AntConc selbst konfigurieren. Gehen Sie im Menü “Settings > Tool settings” in die Kategorie “Keyword ”. Dort können Sie eine Reihe von Parametern definieren, die für einen mathematischen Laien wie Kauderwelsch aussehen. Für das Likelihood-Maß wählen Sie eine Option, z.B. “log-Likelihood (2-term)”, wenn Sie nur 2 Dateien vergleichen wollen. Bei “threshold ” (Schwellenwert) bedeuten kleinere P-Werte strengere Kriterien für den Vergleich mit dem Referenzkorpus. Da vieles von Ihren Rahmenbedingungen (Fachgebiet, Referenzkorpus, Korpusgröße) abhängt, experimentieren Sie mit einigen Konfigurationsalternativen.
Gehen Sie dann auf die Registerkarte “Keywords ” und wählen Sie “sorted by ” + “Likelihood” und klicken Sie auf “Start”. Die Qualität der Ergebnisse hängt von Ihren Einstellungen und der Stärke der semantischen Unterschiede zwischen allgemeinsprachlichem und fachsprachlichem Text ab. Geben Sie nicht gleich beim ersten Ergebnis auf, sondern experimentieren Sie mit einigen Konfigurationen. Leider bietet AntConc nur eine Stichwortsuche auf Einzelwortbasis. Gruppen von 2 oder mehr Wörtern können in AntConc mit dieser Methode nicht direkt analysiert werden.
Es gibt jedoch einen praktischen Workaround für die Keyword-Extraktion von Mehrwortbenennungen:
- Zuerst generieren Sie eine N-Gramm-Liste sowohl für Ihren Zielkorpus als auch für den Referenzkorpus. N-Gramme sind Kombinationen von Wörtern (z.B. Zweiwort- oder Dreiwortgruppen), die in Ihren Texten auftreten.
- Laden Sie diese N-Gramm-Listen anschließend als neue ‘Korpora’ über den Korpus-Builder von AntConc. Dabei behandeln Sie die N-Gramm-Listen wie eigenständige Textkorpora.
- Wählen Sie diese N-Gramm-Korpora aus und erzeugen Sie Schlüsselwörter (Keywords), genau wie Sie es mit normalen Wortlisten tun würden. Diese Methode ermöglicht es Ihnen, signifikante Mehrwortbenennungen zu identifizieren, die in Ihrem Zielkorpus im Vergleich zum Referenzkorpus häufiger oder seltener vorkommen.
Regelbasierte Terminologieextraktion mit Token-Definition und regulären Ausdrücken
Die regelbasierte Terminologieextraktion ist die letzte Methode, die wir hier erwähnen möchten. Auf der Grundlage einzelner Regeln (z.B. „Extrahiere alle Produktnamen, Produktnamen stehen neben der Artikelnummer„) werden die Termini extrahiert, die den definierten Regeln entsprechen.
In AntConc können Sie Regex (reguläre Ausdrücke) verwenden, um sehr spezifische Arten von Tokens (Wörtern) zu definieren, die für Ihre Analyse extrahiert werden sollen. Ein regulärer Ausdruck ist eine Zeichenfolge, die ein Suchmuster definiert, um Texte nach spezifischen Mustern wie Buchstabenkombinationen, Wörtern oder Satzzeichen zu durchsuchen und zu manipulieren. Hier sehen Sie einige Beispiele:
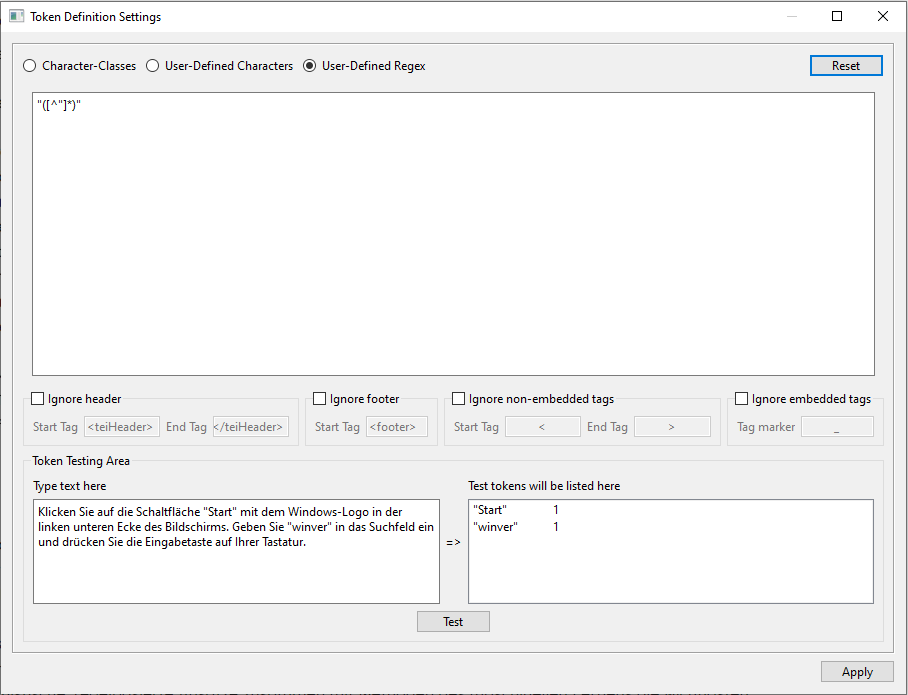
Token-Definition mit Regex in AntConc:
- Öffnen Sie die “Token Definition Settings” in den Basis-Einstellungen Ihres Korpus.
- Wählen Sie die Option “User-Defined Regex”.
- Geben Sie Ihre Regex-Muster in das dafür vorgesehene Feld ein.
Beispiele für Regex-Muster:
- Abkürzungen extrahieren: Um Abkürzungen zu extrahieren, die typischerweise aus Großbuchstaben bestehen und oft durch Punkte getrennt sind, könnten Sie ein Muster wie \b[A-ZÄÖÜa-zäöüß]{1,4}\.(?=\s+[A-ZÄÖÜa-zäöüß]). Dies würde Abkürzungen wie “ca.” oder “Nr.” erfassen und Punkte als Satzendzeichen am Ende des Strings ausschließen. Die definierten Abkürzungen bestehen aus maximal 4 Buchstaben und haben einen Punkt am Ende.
- Wörter in Anführungszeichen extrahieren (z.B. nützlich für die Softwarelokalisierung): Um Wörter oder Phrasen zu extrahieren, die in Anführungszeichen stehen, verwenden Sie ein Muster wie „([^“]*)“ oder ‚([^‘]*)‘. Damit finden Sie Sequenzen, die innerhalb von einfachen oder doppelten Anführungszeichen stehen, etwa “Motor Ein”.
- Text zwischen Tags extrahieren: Wenn Sie Text zwischen HTML- oder XML-Tags extrahieren möchten, könnten Sie ein Muster wie <tag>(.*?)<\/tag> verwenden, wobei tag durch das tatsächliche Tag ersetzt werden muss, nach dem Sie suchen.
Nachdem Sie Ihre Regex-Muster eingegeben haben, können Sie diese testen, indem Sie Beispieltokens in das Feld “Token Testing Area” eingeben und auf “Test” klicken, um zu sehen, welche Tokens generiert werden. Sobald Sie zufrieden sind, klicken Sie auf “Apply”, um die Token-Definition für Ihr Korpus zu übernehmen.
Auf dem Weg zum Experten für Terminologieextraktion
Für Fachleute, die sich mit Terminologiearbeit und -extraktion befassen, ist es unerlässlich, ein tiefes Verständnis für die verschiedenen Methoden der Terminologieextraktion zu entwickeln. Wenn man sich die Zeit nimmt, die Feinheiten und Möglichkeiten von Tools wie AntConc kennenzulernen, kann man die Methoden auf die eigenen Bedürfnisse zuschneiden. Dies führt nicht nur zu einer höheren Effizienz, sondern auch zu genaueren Ergebnissen bei der Terminologieextraktion.
Wir haben AntConc in diesem Artikel als Beispieltool vorgestellt, aber es gibt noch mehrere andere Tools, die für ähnliche Zwecke verwendet werden können. Auch wenn hier nicht alle vorhandenen Methoden zur Terminologieextraktion behandelt wurden, so sind doch statistische, linguistische, regelbasierte Ansätze zusammen mit Methoden des maschinellen Lernens die wichtigsten Säulen in diesem Bereich.
Es ist wichtig zu verstehen, dass die Fähigkeit, solche Ergebnisse zu erzielen, nicht über Nacht entsteht. Sie muss durch beharrliches Ausprobieren erworben und verfeinert werden. Sobald Sie diese Fähigkeit jedoch erworben haben, verfügen Sie über ein leistungsfähiges Werkzeug, das Ihre Terminologiearbeit erheblich vereinfachen und verbessern wird.
Wir wünschen Ihnen viel Spaß auf Ihrem Weg zu mehr Kompetenz in der Terminologieextraktion. Wenn Sie Fragen haben oder weitere Informationen benötigen, zögern Sie bitte nicht, den Autor dieses Artikels zu kontaktieren.