Maschinenbau-Dokumentation lebt von Präzision und Wiederverwendung. Translation Memories (TM) verbinden beides: Einmal übersetzte Sätze (sogenannte 100-%-Matches) müssen nicht neu bezahlt werden, die Durchlaufzeiten sinken und die Konsistenz steigt.
Doch 100-%-Matches täuschen oft Sicherheit vor: Nur weil der Satz identisch ist, heißt das nicht, dass die Übersetzung im aktuellen Kontext auch passt. Hier beginnt das Haftungsrisiko. Manche Unternehmen reagieren darauf mit einer Prüfung aller Matches, was bei Unternehmen mit entsprechendem Übersetzungsaufkommen jährliche Kosten von 20.000 bis 100.000 Euro verursachen kann.
Lohnt sich dieser Aufwand für ein Restrisiko von nur 1–2 %? Es scheint ein Missverhältnis – und doch können manche Fehler so gravierend sein, dass man auf diese Kontrolle nicht verzichten will. Die gute Nachricht: Alles oder nichts muss nicht die einzige Alternative sein.
In diesem Beitrag werfen wir einen praxisnahen Blick darauf, warum 100%-Matches aus Translation Memories nicht automatisch korrekt sind, und zeigen, wie sich durch eine durchdachte TM-Pflege, Segment-Attribute und definierte Prüfprozesse bis zu 95 % der Kosten einsparen lassen – und das bei höherer Qualitätssicherheit.
Grundlagen: Was sind 100-%-Matches und ICE-Matches?
Ein 100-%-Match bedeutet: Der Quellsatz ist zeichenidentisch mit einem bereits übersetzten Segment im TM. Ob die Bedeutung gleich ist, bleibt offen.
Beispiel aus einem TM:
Ausgangssatz (DE): Kontrolle der Anlage
Vorschlag aus dem TM (EN): system control
Doch in derselben Dokumentation finden sich auch:
– plant control (für Produktionsanlage)
– feeder control (für Zuführanlage)
– surface contact control (für Flächenberührung)
Das Problem: Ein 100-%-Match erkennt nur identische Sätze oder Wortfolgen – nicht aber, ob die Übersetzung tatsächlich zum aktuellen Produkt, zur geltenden Norm oder zum Kontext passt. Fehlen diese Zusatzinformationen, kann die Übersetzung falsch sein.
ICE steht für In-Context Exact. Je nach Übersetzungssoftware (CAT-Tool) auch „Kontext-Match” oder „101-%-Match” genannt.
Ein ICE-Match bedeutet: Der Satz und sein unmittelbarer Kontext (vorheriges/nachfolgendes Segment) sind identisch. Das reduziert das Fehlerrisiko deutlich – eliminiert es aber nicht ganz.
Warum? In modularen Redaktionssystemen können identische Kontexte für verschiedene Produkte wiederverwendet werden, die jedoch unterschiedliche Verfahren, Eigenschaften oder Zustände beschreiben.
Die sieben größten Risiken bei Matches
1. Kontextabhängige Bedeutung
Viele technische Begriffe haben je nach Kontext unterschiedliche Bedeutungen:
| BEGRIFF (DE) | KONTEXT A | ÜBERSETZUNG A | KONTEXT B | ÜBERSETZUNG B |
|---|---|---|---|---|
| Widerstand | Bauteil | resistor | Messgröße | resistance |
| Ventil | Pneumatik | pneumatic valve | Überdruck | relief valve |
Hinweis: Ein 100-%-Match würde ohne Kontext-Attribute nur die erste gefundene Variante vorschlagen.
2. Bezugswörter und Pronomen
Ausgangssatz: „Ersetzen Sie es durch ein neues.”
Das Pronomen „es” bezieht sich auf das Hauptwort im vorherigen Satz (Filter, Dichtung, Ventil). Die englische Übersetzung kann nicht beliebig wiederverwendet werden – „Replace it with a new one” funktioniert zwar grammatisch, aber das grammatische Geschlecht oder Numerus in anderen Sprachen (FR, IT, ES) erfordert Anpassungen.
3. Terminologiewandel
Terminologie entwickelt sich. Ältere TM-Einträge können veraltete Begriffe enthalten:
- 2015: „Bedienfeld” → „control panel”
- 2024: „Bedienfeld” → „HMI” (nach neuem Style Guide)
Folge: Uneinheitliche Dokumentation, wenn alte Matches blind übernommen werden.
4. Sprachspezifische Präzision
Manche Sprachen erfordern genauere Unterscheidungen:
- Deutsch: Motor
- Englisch: motor (elektrisch) / engine (Verbrennungsmotor)
Ein 100-%-Match enthält nur eine Variante – die falsche kann übernommen werden.
5. Normen- und Sprachentwicklung
TM bestehen über Jahre. In dieser Zeit ändern sich:
– Sprachgebrauch („Inbetriebnahme” → „Inbetriebsetzung”)
– Normen (EN 82079-1:2012 → 2020)
– Interne Style Guides
6. Kreuzsegmente (kritisch!)
Was sind Kreuzsegmente? Manchmal werden Sätze in zwei oder mehr Segmente aufgeteilt – etwa wegen Layout-Vorgaben oder Zeichenlimits in Displays.
Das Problem: Sprachen haben unterschiedliche Syntax. Was im Deutschen Teil A + Teil B ist, kann in der Übersetzung Teil B + Teil A werden.
Beispiel:
Die Anweisung Hauptschalter auf EIN stellen. wird in einem Display auf zwei Zeilen verteilt.
| SEGMENT | DEUTSCH | ENGLISCH |
|---|---|---|
| 1 | Hauptschalter auf EIN | Set the main switch |
| 2 | stellen. | to ON. |
| 3 | Hauptschalter auf AUS | Set the main switch |
Bei blinder Übernahme aus dem TM können in einer englischsprachigen Dokumentation unerwünschte Kombinationen entsprechen wie:
Hauptschalter auf AUS stellen. → Set the main switch to ON
Folge: Sicherheitsrelevante Fehlanweisung.
7. Fehlerfortpflanzung
Auch geprüfte TM können Schreibfehler oder inhaltliche Fehler enthalten. Diese verbreiten sich ungeprüft – besonders problematisch bei sicherheitsrelevanten Texten.
Sonderfall: Handlungsverben und Handlungsnomen
Handlungsverben und ihre nominalen Formen (spannen / Spannvorrichtung) kommen in technischen Texten häufig vor und sind eine besondere Gefahrenquelle.
Warum?
– Sie werden oft nicht in der Terminologie erfasst, so dass automatische Prüftools sie nicht prüfen können.
– Sie werden in sehr unterschiedlichen Situationen verwendet, die einen unterschiedlichen Ausdruck verlangen.
– Ihre Übersetzung variiert stark je nach Kontext und Zielsprache
| DEUTSCH | KONTEXT | ENGLISCH |
|---|---|---|
| prüfen | Sichtprüfung | inspect |
| prüfen | Funktionsprüfung | test |
| prüfen | Rechnungsprüfung | verify / check |
| einstellen | Parameter | set / adjust |
| einstellen | Betrieb beenden | shut down |
Zusatzrisiko: Post-editierte MÜ-Segmente im TM
Viele TM-Bestände enthalten PEMT-Segmente (post-editierte maschinelle oder LLM-generierte Übersetzung). Das ist oft wirtschaftlich sinnvoll. Problematisch wird es, wenn andere Qualitätsansprüche für solche Übersetzungen gelten (“ich brauche Tausend Seiten in Italienisch bis Montag”) oder wenn Revisoren aufgrund mangelnder Erfahrung mit den Besonderheiten von maschineller Übersetzungen (Siehe unseren Artikel: Vollautomatische Übersetzungen: Traum oder bald Realität?) fehlerhafte Übersetzungen durchgewinkt haben.
Unter den typischen Fehlern von MÜ-Systemen zählen die inkonsistente Terminologieverwendung und bei LLM-generierten Übersetzungen Halluzinationen.
Aus diesem Grund ist es unabdingbar, die Herkunft solcher Übersetzungen in einem Translation-Memory zu kennzeichnen, so dass ein früher „gerade so akzeptabler“ PEMT-Satz nicht später als 100 %-Match ungeprüft übernommen wird.
Die Lösung: Segmentbasierte Prüfung statt Pauschal-Korrektur
Wir bleiben beim Grundgedanken: So wenig prüfen wie nötig, so viel wie erforderlich. Denn es stimmt: Was bereits geprüft wurde, sollte nicht immer wieder geprüft werden. Am Ende entstehen unnötige Aufwände (Zeit und Kosten), die sich vermeiden lassen.
Die Idee ist, ähnlich wie in einer Werkstatt oder im OP, eine Priorisierung vorzunehmen. Basierend auf bestimmten Kriterien wird entschieden, welche 100 %- oder ICE-Matches zu prüfen sind. Das könnte man textbasiert machen:
– bei Dokumenten vom Typ A werden alle 100 %-/ICE-Matches geprüft,
– bei Dokumenten vom Typ B nur die 100 %-Matches,
– bei Dokumenten vom Typ C werden keine Matches geprüft.
Aber: Diese Vorgehensweise passt nicht oft zur heutigen Dokumentationspraxis. Stellen Sie sich eine Reihe von Bedienungsanleitungen für verschiedene Maschinen eines Herstellers vor: Viele Textbausteine – etwa Sicherheitshinweise – sind in fast allen Anleitungen identisch. Es wäre ineffizient, diese Standardtexte bei jedem Projekt erneut zu prüfen.
Bei Maschinen derselben Modellreihe ist das Risiko von Kontextabweichungen gering, solange die Unterschiede zwischen den Modellen eher Aspekte wie Leistung oder Masse betreffen – nicht aber Verfahren. Hier könnte man sich darauf einigen, nur die 100 %-Matches ohne Kontext zu prüfen – oder sogar vollständig auf eine Prüfung zu verzichten, wenn die Maschinen sehr ähnlich sind und die Translation Memories stimmen.
Da Dokumentationen heute jedoch oft über Redaktionssysteme oder CMS generiert werden, würde man bei einer textbasierten Vorgehensweise trotzdem viele Segmente prüfen, ohne dass dies erforderlich ist – etwa Warnhinweise, die in allen Dokumenten gleich sind.
Segmentbasierte Prüfung
Die maximale Einsparung bei hoher Sicherheit besteht also darin, die Prüfung auf Segmentbasis vorzunehmen.
Beispiel:
– Sicherheitshinweise: nicht prüfen (standardisiert, normkonform)
– Produktspezifische Beschreibungen: 100-%-Matches prüfen
– Maschinensoftware-Texte: alle Matches prüfen
So würde man in einem bestimmten Text die 100% Matches aus Sicherheitshinweisen nicht prüfen, jedoch die 100% Matches im übrigen Text.
Segment-Attribuierung für zuverlässige Prozesse
Damit die Prüfung wirklich zielgenau funktioniert, braucht es die richtigen Attribute für jedes Segment im Translation-Memory. Welche das sind, hängt von Ihrer Dokumentation und Ihren Arbeitsabläufen ab – eine Standardlösung gibt es nicht. Hier einige bewährte Beispiele:
Typische Attributkategorien:
| ATTRIBUTTYP | BEISPIELE |
|---|---|
| Produktbezogen | Maschinentyp (X120, E-Series), Verfahren (Hydraulik, Pneumatik) |
| Dokumentationsbezogen | Bedienungsanleitung, Schulungsmaterial, Softwarehandbuch |
| Herkunftsbezogen | Segmentquelle (humanübersetzt, PEMT, NMT), Projektnummer |
| Prüfstatus | Nach ISO 17100 geprüft, einfach korrekturgelesen |
| Sicherheit/Normen | Sicherheitshinweis nach ISO 3864, EN-/ANSI-Referenz |
| Datum | Erstellungs-, Änderungsdatum, letzte Revision |
Beispiel einer Attribuierung:
Segment: „Tragen Sie Schutzhandschuhe.“
Attribute:
– Typ: Sicherheitshinweis
– Norm: ISO 3864-2
– Produkt: alle
– Status: ISO-17100-geprüft
– Datum: 2024-03-15
Dieses Segment muss nicht bei jedem Projekt erneut geprüft werden.
Natürlich wird bei einem 50-seitigen Text niemand jedes Segment manuell mit Attributen versehen. In der Praxis entstehen diese Kennzeichnungen automatisch oder halbautomatisch:
- Viele Attribute lassen sich aus Projekt- oder Dokumentmetadaten ableiten – etwa Produkttyp, Dokumentart oder Revisionsdatum.
- Andere entstehen durch Regeln oder KI-Erkennung, z. B. wenn Sätze mit „Achtung“ oder „Achten Sie darauf, dass …“ automatisch als Sicherheitshinweise markiert werden.
- Auch der Übersetzungs- oder Prüfstatus kann direkt aus dem Workflow übernommen werden.
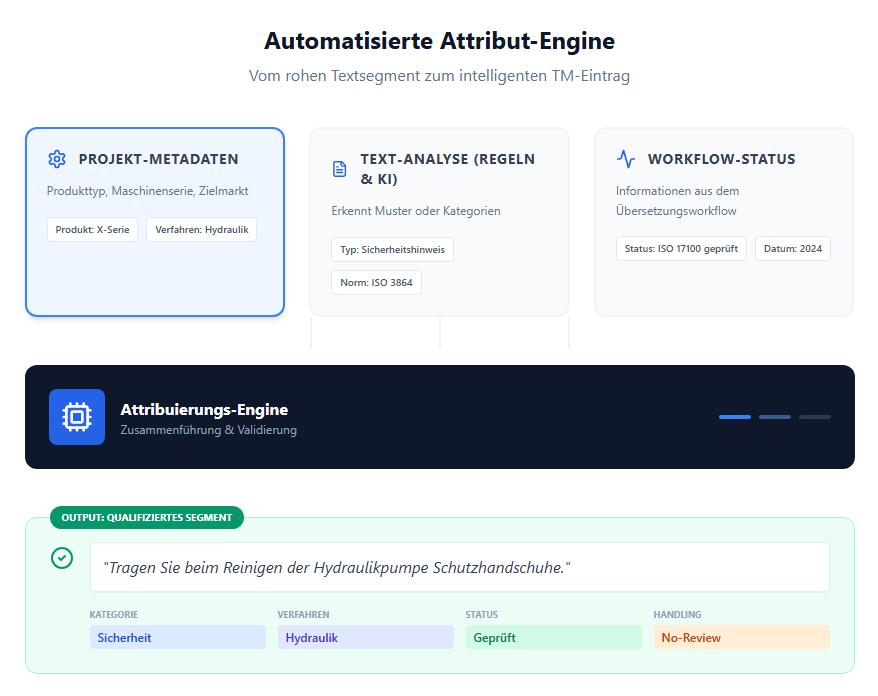
So entsteht eine sinnvolle Attribuierung nicht durch Handarbeit, sondern durch das Zusammenspiel von Daten, Regeln und Prozessen. Nur Sonderfälle – etwa neue Warnhinweise oder geänderte Normtexte – erfordern noch eine manuelle Freigabe.
Standardprozesse definieren: Prüfaufwand dort, wo er zählt
Mit Attributen können Sie Prüfprozesse definieren, die Risiko und Aufwand optimal balancieren.
Beispiel-Prozesse
Prozess 1: Bedienungsanleitungen
– 100-%-Matches: prüfen
– ICE-Matches: nicht prüfen
– Ausnahme: Standardtexte (Warnhinweise, Entsorgung) → nie prüfen
Prozess 2: Maschinensoftware
– 100-%-Matches: prüfen
– ICE-Matches: prüfen
– Grund: Hohe Fehlerkosten, Kontext ist kritisch
Prozess 3: Marketing-Websites
– 100-%-Matches: prüfen
– ICE-Matches: nicht prüfen
– Grund: Weniger sicherheitsrelevant, häufige Updates
Prozess 4: Interne Dokumente
– 100-%-Matches: nicht prüfen
– ICE-Matches: nicht prüfen
– Grund: Geringes Haftungsrisiko
Das Ergebnis
- Weniger manuelle Prüfung gesamt
- Aber genau dort, wo sie zählt
- Geringeres Haftungsrisiko
- Budget-Einsparung
Voraussetzung: Saubere Datenbasis
Die beschriebenen Prozesse funktionieren nur mit gepflegten Daten. Das betrifft drei Bereiche:
1. Translation Memory Pflege
Aufgaben:
– Veraltete Segmente entfernen
– Duplikate bereinigen
– PEMT-Segmente kennzeichnen
– Attribute ergänzen/aktualisieren
Aufwand: Regelmäßig, etwa monatlich
2. Terminologie-Management
Aufgaben:
– Firmenterminologie mehrsprachig pflegen
– Kontextabhängige Begriffe dokumentieren
– Relevante Handlungsverben systematisch erfassen
– Terminologie-Tools in Übersetzungsprozess integrieren
3. Quelltext-Optimierung
Das Problem: Minimale Unterschiede erzeugen neue Matches.
Beispiele:
| VARIANTE 1 (DE) | VARIANTE 2 (DE) | VARIANTE 1 (EN) | VARIANTE 2 (EN) |
|---|---|---|---|
| Einstellungen aufrufen | Einstellungen aufrufen. [Unterschied ist ein Punkt am Ende] | Select settings | Open settings. |
| Motor starten | Den Motor starten | Start motor | Start the engine |
Lösung: Controlled Language, Style Guides, automatische Prüftools (z.B. Congree, Acrolinx)
Ausblick: Übersetzungsprozesse im KI-Zeitalter
Dieser Artikel fokussiert auf 100-%- und ICE-Matches aus Translation Memories. Doch das Prinzip – standardisierte Prozesse mit gezielter menschlicher Qualitätssicherung – gilt zunehmend für die gesamte Übersetzungsproduktion:
- MÜ- oder LLM-generierte Rohübersetzungen ersetzen zunehmend klassische Humanübersetzung
- Automatisierte Qualitätsprüfung durch regelbasierten und KI-Tools
- Menschliche Prüfung nur dort, wo sie echten Mehrwert bietet
Das ist der Weg, wie Übersetzungen morgen produziert werden. Übersetzer und Linguisten wird man selbstverständlich weiterhin benötigen. Ergänzt werden sie jedoch durch neue Berufsprofile, etwa den „Übersetzungskonstrukteur“, der Prozesse, Qualitätssicherung und KI-Systeme steuert.
Glossar
Translation Memory (TM): Datenbank mit bereits übersetzten Segmenten, die bei neuen Projekten wiederverwendet werden können.
Segment: Kleinste Übersetzungseinheit, meist ein Satz oder Teil davon.
100-%-Match: Quellsatz ist zeichenidentisch mit einem TM-Eintrag.
ICE-Match / 101-%-Match: Satz und Kontext sind identisch mit einem TM-Eintrag.
PEMT: Post-Edited Machine Translation – maschinell übersetzt, dann manuell korrigiert.
Attribut: Metadaten-Eigenschaft eines TM-Segments (z.B. Dokumenttyp, Prüfstatus, Datum).
Controlled Language: Regelwerk zur Vereinheitlichung von Texten (begrenzte Terminologie, standardisierte Satzstrukturen).
LLM: Large Language Model – KI-Modell für Sprachverarbeitung (z.B. GPT, Claude).
Halluzination: KI-generierter Inhalt, der nicht im Ausgangstext vorhanden war.
Haben Sie Fragen zur Implementierung? Kontaktieren Sie uns für eine individuelle Beratung.